AI绘图基础参数
1、点击左侧导航栏“AI绘图”按钮进入图像生成栏目。
2、提示词 (Prompt)
提示词 (Prompt) 是用户向 AI 模型提供的文本描述或指令,用来引导模型生成图像的基本内容。它是 AI 绘图的核心输入之一,直接影响生成结果的质量和准确性。
提示词可以简单如“猫”,也可以非常复杂如“夕阳下的森林,远处有一座古老的城堡,空气中弥漫着金色的光芒”。这些文字告诉模型你想要什么样的图像,模型会根据这些文字信息进行图像的生成。
AI 绘图模型会将用户的提示词与已有的大量图像数据进行匹配,并根据语义生成符合提示的图像。提示词的丰富性和具体性对于图像生成至关重要。简单的提示词通常会导致模糊或过于普通的图像,而详细且具体的提示词则能帮助模型更精确地理解创意,并生成更具个性化和高质量的作品。
通常,提示词包括描述图像的对象、风格、场景、光影等元素。例如,描述一个“森林中的狐狸,清晨的阳光透过树叶洒在草地上”,模型不仅需要理解“狐狸”和“森林”是什么,还需要捕捉到“清晨的阳光”和“草地上洒的光影”等细节。
有效的提示词使用不仅仅是精准描述,更是要根据模型的训练特点来调整词汇和结构。例如,某些模型对“拍摄角度”或“艺术风格”的描述反应较好,而其他模型则可能对具体的色彩或情感的描述更敏感。因此,在不同的模型中,提示词的优化策略也有所不同。
提示词优化技巧:
- 具体化:避免模糊不清的描述,尽量提供清晰的细节。
- 风格化:如果你希望生成某种特定风格的图像,可以明确指出,例如“梵高风格的星空”。
- 情感化:通过语言传达图像应有的情感,如“悲伤的景象”、“充满希望的阳光”等。

3、负向提示词 (Negative Prompt)
负向提示词 (Negative Prompt) 是与提示词相对的概念,用于告诉 AI 模型在生成图像时应该避免出现哪些元素或特征。它为生成过程提供了负向引导,帮助模型排除不希望出现的内容。负向提示词通过明确限制,能够在某些情况下改善图像的质量,使生成结果更符合预期。
例如,假设你希望生成一幅风景画,但不希望图像中出现建筑物。你可以在负向提示词中写上“建筑”。这样,模型在生成图像时会避免包括建筑物的元素,帮助你获得符合要求的风景图。
负向提示词的应用非常广泛,尤其在以下几种场景中:
- 避免不必要的细节:比如,在人物肖像生成时,可能希望避免过多的背景元素或杂乱的颜色。
- 避免风格错误:例如,你可能希望生成某种艺术风格的图像,但不希望它过于现代或卡通化,那么可以通过负向提示词进行限制。
- 清除偏差:AI 绘图模型可能会受到训练数据中的某些偏差影响,负向提示词能够帮助消除这些潜在的负面影响,确保生成的图像符合预期的审美。

4、模型主题 (Checkpoint)
Checkpoint 是 AI 模型训练过程中的一个保存点,用于记录模型的状态、权重和参数。这一概念最初源于深度学习领域,在模型训练过程中,每经过一定的训练周期,系统会将当前的模型状态保存为一个“checkpoint”。该保存点包含了当前训练模型的所有参数、权重、超参数设置等信息。
Checkpoint 在 AI 绘图中的应用:
在 AI 绘图中,Checkpoint 是指保存模型训练结果的文件,它代表了模型的某个阶段。在生成图像时,Checkpoint 文件不仅包含模型的参数,还涉及到特定的训练数据和生成能力。不同的 Checkpoint 文件会影响模型生成的风格、细节及其多样性。
例如,在图像生成模型中,Checkpoint 文件包含了模型在各种图像生成任务中训练得到的权重,决定了图像生成的风格和细节层次。选择不同的 Checkpoint 可以生成不同风格或主题的图像,或者对生成内容进行微调。
Checkpoint 的工作机制:
- 训练保存:在训练过程中,模型的每个阶段都可以保存一个 Checkpoint 文件。如果训练过程因故中断,可以通过恢复最近的 Checkpoint 继续训练,避免从头开始。
- 风格和质量:不同的 Checkpoint 文件对应不同的生成风格或质量。比如,有些 Checkpoint 是专门训练以生成细腻的肖像图像,有些则专注于生成高度抽象的艺术作品。通过更换 Checkpoint,用户可以在不同风格之间切换。
使用 Checkpoint 的优点:
- 节省时间:Checkpoint 可以避免重复训练,大大加速了模型的迭代和实验过程。
- 灵活性:用户可以根据需要加载不同的 Checkpoint,快速调整生成的风格或任务。例如,想要生成某个特定艺术风格的图像时,只需要加载该风格相关的 Checkpoint 文件。
- 兼容性:Checkpoint 使得多个不同的模型或数据集可以被无缝结合,提供更多的可能性和灵活性。

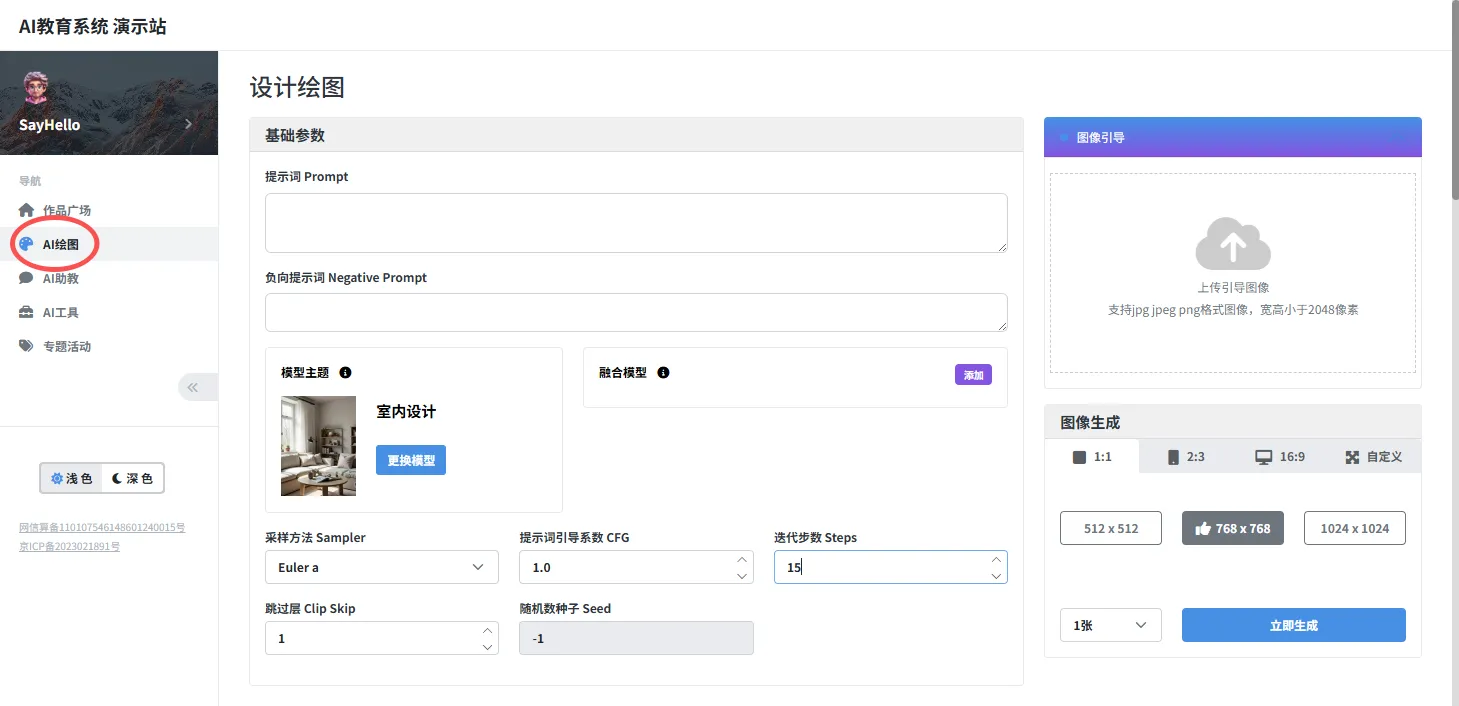
5、融合模型(LoRA)
LoRA(Low-Rank Adaptation)是一种创新的模型适配技术,用于增强大规模预训练模型的能力,特别是在资源受限的环境中。LoRA 的主要作用是通过低秩矩阵(low-rank matrix)来对预训练模型进行微调和适配,避免了全量参数更新,从而大幅降低了训练成本。
LoRA 的工作原理
LoRA 的核心思想是将预训练的模型与低秩矩阵结合,通过训练一个较小的低秩矩阵来改进模型性能,而不是直接训练整个模型的所有参数。这样,模型的主要结构和预训练的权重保持不变,只对低秩矩阵进行微调。
- 低秩矩阵:通过这种方式,LoRA 使用的低秩矩阵相较于传统方法大大减少了需要更新的参数数量。这不仅降低了计算资源的消耗,也缩短了训练时间。
- 灵活性与适应性:LoRA 可以通过对低秩矩阵的调整,使得模型能够适应不同的任务需求,并保持高效的性能。
LoRA 在 AI 绘图中的应用
在 AI 绘图中,LoRA 可以通过对预训练模型进行微调,优化图像生成的效果。比如可以通过 LoRA 来针对特定风格进行微调,以生成具有独特艺术风格的图像,而无需从头开始训练一个新模型。
例如,在生成动漫风格图像时,LoRA 可以通过调整少量参数,帮助模型更好地适应特定风格,生成出符合用户要求的图像。此外,LoRA 的低秩适配方式,可以为小型设备或低资源环境下的模型微调提供解决方案,这使得 AI 绘图的应用更加普及和灵活。
LoRA 的优点:
- 资源节省:相比传统的微调方法,LoRA 可以大幅减少模型参数的更新量,节省了大量的计算资源和存储空间。
- 快速适配:LoRA 可以让预训练模型快速适应新任务或新领域,无需重新训练整个模型。
- 高效性:LoRA 在提升模型性能的同时,不会显著增加计算负担,因此适用于实时或高并发的生成任务。
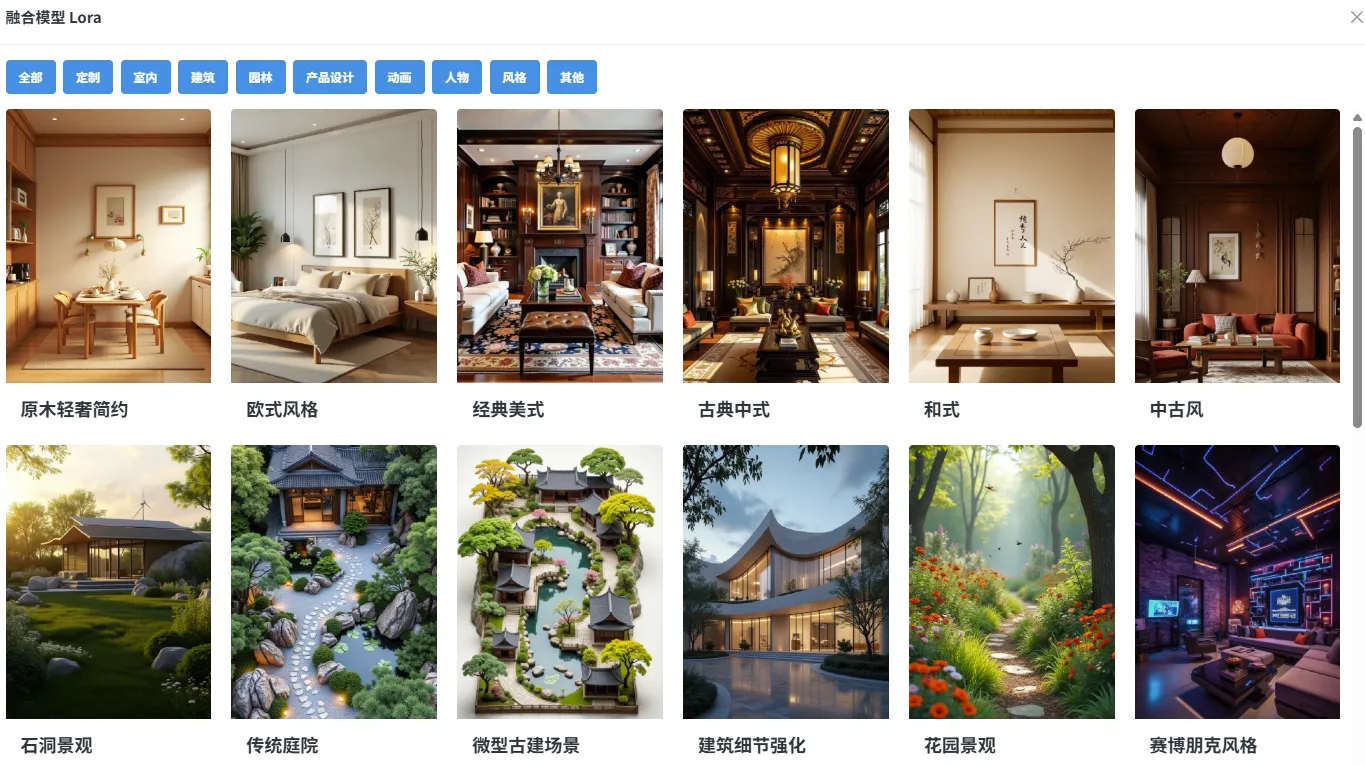
6、采样方法 (Sampler)
采样方法 (Sampler) 是 AI 绘图模型中用于生成图像的算法或策略。采样方法定义了模型如何从潜在空间(即生成的所有可能图像)中选择最可能的图像。在扩散模型中,采样是生成过程中至关重要的部分,它决定了生成图像的质量、速度和多样性。
扩散模型的核心理念是通过在噪声图像上进行迭代,逐步恢复出真实的图像。在这个过程中,采样方法控制着如何从随机噪声中采样,并最终产生一个符合提示词描述的图像。
常见的采样方法包括:
- DDIM (Denoising Diffusion Implicit Models):这是一种高效的采样方法,它通过在每个步骤进行更少的计算来减少生成过程中的时间消耗,同时能够保持图像的质量。
- LMS (Laplacian Pyramid Sampling):该方法使用拉普拉斯金字塔来提高图像细节和纹理的表达,使图像的细节更加丰富。
- PLMS (Pseudo-Laplacian Pyramid Sampling):PLMS 是对 LMS 方法的优化,通过减少迭代次数来提升采样效率。
每种采样方法都有不同的优点和适用场景,开发者可以根据图像的需求(如生成速度、质量要求)选择适合的采样策略。
采样方法选择的影响:
- 图像质量:不同的采样方法生成的图像质量会有所不同,有些方法适合高质量图像,而有些则适合快速生成低质量图像。
- 生成速度:不同采样方法在生成图像时消耗的计算资源和时间也各不相同。
7、提示词引导系数 (CFG - Classifier-Free Guidance)
提示词引导系数 (CFG),或称为 无分类器引导,是一种控制 AI 图像生成过程中的提示词强度的方法。CFG 通过调节提示词对生成图像的影响程度,使得图像与用户输入的提示词保持一致。
在生成过程中,AI 模型会根据提示词的内容生成图像,但有时生成的结果可能与提示词不完全匹配。为了控制这种偏差,CFG 引入了一个权重参数,用于调整模型生成图像时如何“倾向”于提示词的内容。CFG 值越高,生成图像与提示词的匹配度就越高;CFG 值越低,生成的图像会更具随机性和创意。
例如,在生成一幅“未来城市”的图像时,如果 CFG 设置较低,模型可能会尝试结合更多的创意元素,生成一些非典型的、科幻感十足的图像;而如果 CFG 设置较高,模型会尽量确保生成的城市图像符合我们传统认知中的“未来城市”样式,例如高楼、飞车等元素。

8、迭代步数 (Steps)
迭代步数 (Steps) 是 AI 绘图生成过程中,模型对图像进行优化和调整的次数。每一次迭代,模型都会逐步改善图像的细节,去除噪声,向最终图像的目标方向靠近。迭代步数越多,图像的质量和细节通常越高,但生成的时间也会增加。
在 扩散模型 中,每一个“步”实际上是一个去噪过程。每步模型都会将图像的一些噪点去除,逐步接近清晰和真实的状态。适当增加迭代步数,尤其是在生成高质量图像时,可以显著提升结果的细节和准确性。然而,增加步数也会增加计算开销,降低生成速度。

9、跳过层 (Clip Skip)
跳过层 (Clip Skip) 是在图像生成过程中,跳过某些神经网络层的输出,以此来减少模型计算量或改变生成图像的风格或细节。具体来说,模型中的某些层负责提取特定的图像特征,而跳过这些层可能导致不同的风格或细节特征。
例如,跳过某些“高层”特征层,可以使生成的图像更加抽象或模糊;而保留这些层,图像则可能变得更加清晰和细致。调整 Clip Skip 值能够帮助用户定制图像的风格,获得更加符合预期的视觉效果。

10、随机数种子 (Seed)
随机数种子 (Seed) 是用来初始化随机过程的数值。在 AI 图像生成中,随机数种子决定了图像生成过程中的随机性。每次生成图像时,即便使用相同的提示词和其他参数,随机数种子的不同也会导致完全不同的图像。通过设定特定的种子值,用户可以确保每次生成的图像一致,从而进行批量处理或

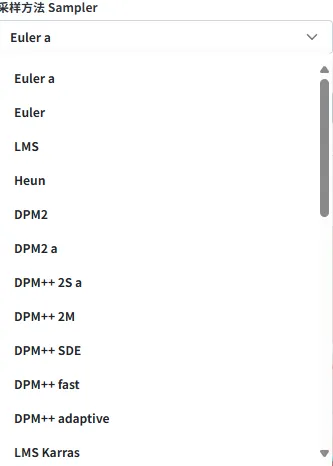
11、图像尺寸
系统内置了 1:1、2:3、16:9 三种常见的图像比例,用户可以根据生成内容的需求选择合适的比例。每种比例下,提供了三种不同的图像尺寸供选择,以满足不同的使用场景和需求。同时,系统还支持自定义尺寸,用户可以灵活选择 512px 到 1536px 的任意尺寸,以适应更细化的图像需求。
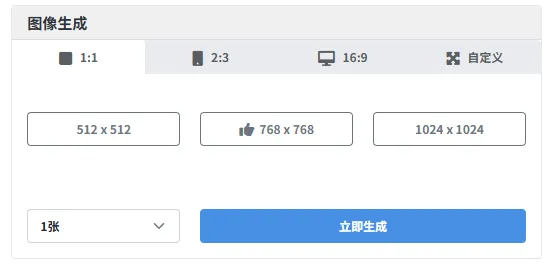
注1: 带有标识的尺寸为当前主题模型推荐尺寸,通常此图像尺寸可以获得更加的生图表现。
带有标识的尺寸为当前主题模型推荐尺寸,通常此图像尺寸可以获得更加的生图表现。